We bought our house in April. When we moved in, my office had about fifty boxes in it. Every few weekends I'd manage to unpack a couple of boxes, many of which just had old, recyclable mail and printouts of source code that needed shredding.
Yesterday I finally made it down to six boxes, a real achievement, and so I celebrated with a quick trip to Ikea to dedicate a corner of my room to a quiet space.
I like the freestanding shelf. I've never put one up before. I can see adding a second shelf underneath it.
The rug not only helps define the space, but now there's someplace in my office where Maggie can always sit (as demonstrated in the photo.)
Now I'm no design star, which is why everything is black, but I'm very happy. A clean, empty space.
Next week I'm getting a second chair, a second shelf, and a plant. What else?
Yesteday the M4 release of Eclipse 3.6 was announced, and in the New and Noteworthy is my recent contribution:
In JUnit launch configurations, you can now edit the test method:
When the test method is empty, all tests in the class will be run.
The particular thing about this feature is that it was already possible to have a single method under test, but it was only available in an arcane way, through a launch shortcut. Select an individual method in the Eclipse editor (I imagine it's also possibly available through an outline or other such adapted view), right-click and select Run As > JUnit Test.
My hope isn't that a small feature like this makes Eclipse more powerful, but that it makes you more powerful. Give it a try and provide feedback on the bug report.
Powerful features lose their worth if people don't know about them, and people won't find out about powerful features if they're hard to find. Word-of-mouth only goes so far.
Whether or not you believe Eclipse users suffer death from a thousand paper cuts (I do like that matrix), every tool has its rough edges. What small usability feature do you think would make a difference?
JetBrains just announced the release of IntelliJ 9, which also comes with its new Community Edition! Congratulations, JetBrains!
The primary reason I was interested in Eclipse years past was because it was free and better than NetBeans; I could go from one job to another and not have to ask for an IntelliJ license. But I've always wanted to play with it. The final selling point to me was Eric Burke's IDE matrix. The day to start trying out IntelliJ has come now that a free version is available.
I'm playing with it tonight. Everything is familiar yet entirely foreign. I imagine that someone recovering from a stroke, learning to use his hands for the second time, might have similar (albeit more striking) frustration while realizing fingers don't magically go where they're supposed to.
My day job is providing tools and support to the Eclipse users at Google. We have quite a few Eclipse users at Google, but we also have quite a few IntelliJ users at Google. And it's not a terribly inaccurate characterization that the IntelliJ users at Google love IntelliJ. The folks that love it are colleagues I admire; Jetbrains must be doing something right.
If you use the Eclipse IDE to write your software, I encourage you to download IntelliJ and take it for a spin. See what you like, see what you don't. And then, report back. Sharing ideas from other communities can make a big difference to an open community.
Unless you fell into that "Tragedy of the Commons" conversation, in which case we're all screwed.
This weekend I rented a car with Budget. I declined their fuel service option since I knew I was driving a relatively short distance, and there are plenty of gas stations near the rental station. I could easily fill the tank. Since I am a member of their RapidRez program, I didn't need to go in to the office; I picked up my paperwork literally on the way out of the airport parking lot, put it aside, and drove to the city.
Sunday night I paid $8 to fill the gas tank, and returned the car. Some rental facilities give you a bill as you drop off the vehicle, but at this location I was directed to the office, where I picked up the paperwork. I looked it over quickly and noticed a $14 fee. (Okay, it was a $13.99 fee but the only two groups of people who suggest those numbers are unequal are marketers and mathematicians.) I asked the agent about the fee, and I was pointed to a small sign regarding their new policy:
EZ Fuel
If you drive fewer than 75 miles, save time and do not refill the tank. Budget will automatically add a charge to the rental for fuel. If you do refill the tank, simply present a receipt and Budget will remove the charge.
Apparently I was given a piece of paper regarding this policy when I left the parking lot. But I wasn't asked to sign anything, nor was I aware of it when I handed the forms to my passenger and drove off the lot. I explained to the agent that I filled the tank, but could not find the receipt. The agent insisted I was still responsible for the charge. I told the agent that there was no way I was paying for this. The agent insisted I was liable without the receipt. I stood my ground. I repeatedly pointed to the slip of paper provided by the person who collected my car that indicated a) no damage and b) a full tank of gas. It was only when I asked to speak with the manager that they removed the fee.
There are so many things I dislike about this fee: this article, suggests they're banking on your unwillingness to argue for the refund. They're hoping you run for the shuttle, or not even notice. I wonder if the typical profile of an airport renter who drives less than 75 miles is the businessperson in for the day, people who are seriously counting minutes. I, too, would have not argued for a refund if I returned the car as originally planned Monday morning 9AM, instead of Sunday 11:55PM when I was the sole customer in the office.
I can imagine they want to recoup costs for their one-gallon consumers. Here's a solution: raise your rates. Of course, they won't; they want to maintain their competitive advertised rates, in the same way airlines charge for meals. Here's another idea: charge a sliding scale based on the vehicle's fuel efficiency. They won't do that either: it's easy to have a flat fee, and it will encourage customers to rent the more fuel efficient cars, for which they charge less. OK, here's another idea: stop relying on mediocre analog fuel gauges for your measurements. That also has problems. Here's another: don't make me come to your office to get a receipt.
So is it worth ensuring I drive more than 75 miles just to avoid the fee? At $3 per gallon, a car that gets 16 miles to the gallon will need $14 of fuel to travel 75 miles. What's the right strategy to execute when driving to an airport in an unfamiliar location when your odometer reads 73.5 miles?
I've only used Budget because they provide a RapidRez card to my company's employees. It's not worth this. Even though I am certain to drive 300 miles when I return to Los Angeles in January, I'm going with Enterprise.
Well, and here's why my job is damn cool: after discovering this issue, I dropped a note to Josh Bloch, who quickly replied: (edited summary)
Yes, this is a pain. FWIW, it was done for a very good reason: compatibility with Perl. The guy who did it is Mike "madbot" McCloskey, who now works with us at Google. Mike made sure that Java's regular expressions passed virtually every one of the 30K Perl regular expression tests (and ran faster).
I have no real issues with the way Madbot implemented regular expressions in Java, nor with the goal of Perl compatibility. Perl's regular expression language was very popular, and derivatives of it were implemented not only in Java, but , JavaScript, PCRE, Python, Ruby, Microsoft's .NET Framework, and the W3C's XML Schema.[ref]
But I do have issue with String getting saddled with a method that quietly explodes the API's complexity.
So why does Perl work this way? I don't know, dude. This isn't a Perl Puzzler.
However, I tried to recreate the original puzzler in Perl as a way to validate the original puzzler's behavior. Unfortunately, I failed using perl v5.8.8 on my OSX machine. This script:
I'm not claiming there's either a bug or implementation change in either the Java or Perl implementations, but I sure am curious.
Possible Solutions
1. Hacking String.split
I don't attest to this, but it seems that you can ensure consistent behavior by appending a copy of the delimiter. So, if you plan to split a string by its colons you can do:
String[] result = (string + ":").split(":")
I'm sure you can find all sorts of issues with this example. Go for it. Point them out in the comments.
public class Main {
public static void main(String[] args) {
tokenize("");
tokenize(":");
tokenize("a:");
tokenize(":a");
tokenize("a:a");
tokenize("::");
}
static void tokenize(String s) {
StringTokenizer t = new StringTokenizer(s, ":");
List l = new ArrayList();
while (t.hasMoreTokens()) {
l.add(t.nextToken());
}
System.out.printf("Tokenization of %s is %s\n", s, l);
}
}
yields
Tokenization of is []
Tokenization of : is []
Tokenization of a: is [a]
Tokenization of :a is [a]
Tokenization of a:a is [a, a]
Tokenization of :: is []
3. Get your serving of Guava.
Here's a nice one: Project Guava. Project Guava is a soon-to-be open sourced library some of Google's core Java code. I've worked with these libraries for five years and I attest that they're wonderful to use. The only problem: it's not out yet. Kevin Bourrillion tells me. though, that an initial release will be available before Thanksgiving.
Note: You may already be aware of the open source project for Google's collections library. When Guava is released, the Google Collections library will go away.
The Guava libraries have a class called Splitter. Splitter's purpose is to alleviate some the confusion that comes with String.split.
By default Splitter's behavior is very simplistic:
Splitter.on(',').split("foo,,bar, quux")
This returns an iterable containing ["foo", "", "bar", " quux"]. Notice that the splitter does not assume that you want empty strings removed, or that you wish to trim whitespace. If you want features like these, simply ask for them:
private static final Splitter MY_SPLITTER = Splitter.on(',')
.trimResults()
.omitEmptyStrings();
You can read more about Guava in Kevin Bourrillion's presentation slide deck from September of this year. Splitter is covered in slides 13 to 17.
Avoiding the real issue
There are two ways of looking back on the variety of votes: either people were assuming that String.split had confusing behavior, or they just expected it to work as as they would hope. Some might want a parse of ":" to return two elements. Some might want it to return one. Or zero. Something as seemingly simple as string tokenization has behavior that just might not meet your expectations. I'd like to say that Guava'sSplitter will do the trick for everyone (as it does for my case of parsing a classpath) but you need to evaluate it for yourself.
This has been a rather long way of saying: test your edge cases. Thanks for reading.
Update: I fixed some small errors, and also updated the charts one last time.
This blog post contains the results and answer to the previous post, Splitting Hairs.
Given the nature of the possible answers, this is actually two puzzlers in one:
How many elements come back from "".split(":"): Zero or one?
How many elements come back from ":".split(":"): Zero, one or two?
Darn, I could have gotten two separate puzzlers out of this.
My Guess
Here's the important point: this is a real world case that occurred to me just the other day. Specifically, I was writing some UI code to edit and parse a colon-separated classpath, so in fact the line in question looked like this:
In this case, if the UI field starts out empty, and classpathField.getText()returns an empty String. Effectively, my expectation was that with an empty classpath, I'd also get an empty array.
So my guess for "".split(":").length() is Zero.
My guess for splitting a separator would result in two empty strings on either side. So that guess is two. Put them together and you get c) 0/2.
Your Guesses
How did you folks do?
Let's look at the numbers:
An overwhelming preference for f) 1/2, and my guess, c) 0/2 in a distant second.
The Answer
If by now you haven't run the sample code, I'll tell you: the correct answer is d) 1/0. If you're shocked that you get more elements with less data, you're not alone. Hey, just look at those graphs.
Okay, let's start the analysis by reading the method signature for String.split():
public String[] split(String regex)
Ah, yes, split takes a regular expression as a delimiter, not a literal string.
Sidebar: I occasionally read about (or experience) puzzlers where someone tries splitting on a pipe character (|), which has a special meaning in regular expressions. To split on a pipe, you must use "\|" so the pattern compiler sees it as a literal character. This is not one of those puzzlers: the colon does not have a special meaning for the pattern compiler.
Part 1: "".split(":")
If you navigate through the source for String.split, you'll discover that "".split(":") is effectively the same as Pattern.compile(":").split("", 0).
OK, that explains the first one, what about the second one?
Part 2: ":".split(":")
To understand what's going on, let's look again at the javadoc for Pattern.split(). In this case, n by the nature of being called by String.split(String), is 0.
If n is zero then the pattern will be applied as many times as possible, the array can have any length, and trailing empty strings will be discarded. [ emphasis added. ]
This can be corroborated with this piece of code near the end of the method:
// Construct result
int resultSize = matchList.size();
if (limit == 0)
while (resultSize > 0 && matchList.get(resultSize-1).equals(""))
resultSize--;
In other words, internally, it splits the input string ":" into [ "", "" ], and then removes the elements before returning to the caller, but "".split(":") doesn't get this treatment because the delimiter was never found in the input.
Does your head hurt? Mine sure hurts, and I've done the research. But here, if you're still hungry, or hate yourself, take a look at this little gem, almost worthy of its own puzzler.
This is the final in a series of posts about a puzzler [ post containing the question ] [ post containing the answer ]. In those two posts I highlighted some bizarre Java weirdness as it pertained to the java.io.File.getCanonicalPath method, that canonicalized paths are cached, which means if a symbolic link changes somewhere the cached value becomes invalid.
Blatherberg
This problem really only ever crops up when your code relies on calls to getCanonicalPath and the links change while the application is running. If you expect your application to run against a filesystem with shifting symbolic links, you have to do one of these three things:
Disable the cache by setting the system property sun.io.useCanonCaches to false. (I would also like to briefly nod to the pedantic point that the string useCanonCaches is icky.)
This seems like an easy out (particularly if your application is moderately complex, and deployed, and assuming your application doesn't rely on the default behavior,) but there's a reason Java comes with a canonicalization cache: performance. Reading symbolic links from disk can take time, especially if you do it a lot.
Also, you might be running your application in a Java EE container along with other applications, in which case, you can't isolate the cache behavior to a single application.
Stop using getCanonicalPath (and its sugary sibling, getCanonicalFile) in your application, and rely solely on the non-canonicalized path.
Changing your infrastructure to rely on the symlink paths themselves and not their canonicalized values sounds good, but you might not have control over that code: your application may rely on an application infrastructure that already relies on getCanonicalPath, and then you're kind of screwed. It's easy to say that the cache should be disabled in the name of correctness, but if you're repeatedly resolving symbolic links files by the thousand, the time cost may be significant.
This leads to the other way to look at this problem, which is the lack of accessibility and flexible control over the cache. You might want to cache calls in some circumstances yet not others. The use cases for cache control can be complex, and by hiding the complexity you get, well, surprises like this.
Disallow an application's filesystem to redefine symbolic links.
If you've got that power, go for it.
Help From JSR 203
There's actually some hope for the future, and that's JSR203: More New I/O APIs for the JavaTM Platform ("NIO.2") which is scheduled to be part of Java 7. Look back to the puzzler, which points out the use of Filesystem and UnixFilesystem classes. In JSR203, those ideas are explicit. The equivalent of java.io.File is java.nio.file.Path which exposes a method getFileSystem. That's right, the file system is no longer hidden from the user, and you can read all about java.nio.file.FileSystem here. You can have a file system that represents a thin layer on top of your disk, or one that caches all sorts of metadata from your disk, or, heck, create an in-memory implementation for high-speed storage! But the real benefit is that these filesystem implementations can be injected into your classes: no more need for a single static filesystem. Whereas java.io.File objects are created through a constructor, java.nio.file.Path objects are constructed through the FileSystem's getPath method.
This isn't disk i/o nirvana, unfortunately, because like the continuing transition from java.util.Date to java.util.Calendar to something more reasonable like org.joda.time.DateTime, there's still plenty of legacy code using the old and busted APIs. But it's a good start.
If you want some more information about JSR 203, here's a write-up by Alex Miller and a link to a JavaOne talk from 2008. The video is a bit out of date (for instance it highlights the notion of Path.get, which seems to be gone, thank goodness.) But it's got lots of great information about the JSR.
The Last Word
In the end, I want to highlight something underlying this entire journey: the choice to cache the values by default in the first place is just wrong. It reminds me of the saying (that seems to be attributed to Bill Harlan): "It's easier to optimize correct code than it is to correct optimized code.
This blog post contains the results and answer to the previous post, A Symbolic Puzzler.
The answer will be covered here, and I'll follow this up with a fourth post that covers my thoughts on this issue.
What were your guesses?
Clearly, the most popular answer was that the test would fail.
What would have been my guess?
Look, nobody codes in puzzler fashion, so without details I'll explain what I expected to occur from my own production code, but in terms of this test. I wouldn't be confident that TESTDIR_SYMLINK.getCanonicalPath() returned the non-canonicalized location, but excepting that, I certainly would assume that once the symbolic link was created at the end, the second call to TESTDIR_SYMLINK.getCanonicalPath()would return the symlinked directory. So my guess would have been a. It passes.
The Answer
The correct answer is: d. It depends. More specifically, it depends on the VM's arguments.
The Explanation
If you ran this test straight up without any special VM arguments, the test would fail (which might lead you to think the answer is b. It fails.)
junit.framework.ComparisonFailure: expected:</testdir/[file]> but was:</testdir/[symlink]>
at junit.framework.Assert.assertEquals(Assert.java:81)
at junit.framework.Assert.assertEquals(Assert.java:87)
at ATest.testSymlink(ATest.java:26)
...
Why wouldn't the canonicalization return the updated value? It's because the return value from getCanonicalPath was cached from the previous call. Yes, calls to getCanonicalPath are cached.
Let's look at the code underneath getCanonicalPath. The magic lies in some package-private classes in the java.io package, specfically Filesystem and UnixFilesystem. The key operation occurs in UnixFilesystem.canonicalize:
class UnixFileSystem extends FileSystem {
public String canonicalize(String path) throws IOException {
if (!useCanonCaches) {
return canonicalize0(path);
} else {
String res = cache.get(path);
...
}
}
private native String canonicalize0(String path) throws IOException;
}
In other words, the path canonicalization computations are cached when useCanonCaches is true. So just when is useCanonCaches true? For that let's look at the static initialization block for Filesystem, the subclass of UnixFilesystem:
So by default, the cache canonicalization is on, but when you specify the VM arg -Dsun.io.useCanonCaches=false, the cache is never used.
Getting back to the puzzler, the first call to TESTDIR_SYMLINK.getCanonicalPath() always returns the path to the symlink, while the second call returns either the cached value (the path to the symlink) or the up-to-date resolved symlink, but only when -Dsun.io.useCanonCaches=false is specified.
If you don't beleive me now, go try running the test twice, once without specifying VM arguments, and once while disabling the canonicalization cache, and you'll see that it fails once, and passes another time. Hence, d. It depends.
Replies to some of the comments
Here are some of the comments that accompanied the survey:
Guess: It fails. Comment:The target of the symlink doesn't exist so I suspect exists() will return false
In fact, exists() will return true since the symlink exists. And in fact, the next call to getCanonicalPath returns itself, just as the comment suggested.
Guess: It depends. Comment: Depending on where the root filesystem is mounted, the canonical path might be something else. For example, /etc on Mac is a symlink to /private/etc. In addition, the mountpoint for / might be a networked drive (e.g. netboot) which might have different semantics.
The bottom line is that you can't necessarily assume that the file you use to access a file is the canonical path for that file, without knowing the filesystem.
This is an interesting comment. I had hoped this was cleared up by this statement in the original post: "The path /testdir is not a symbolic link to another directory, and the user running the test also owns /testdir." If my explanation was insufficient, then so be it.
There were other comments to that effect: "Does /bin/rm do what /bin/rm should do?" "Does the user have write permissions?" These are good points, and would be better suited for a UNIX puzzler. I hope people who worried about those cases looked past them to focus on Java's behavior.
Guess: It throws an exception Comment: I want be the first one to check "it throws an exception"!
Sorry, not the first.
Meta: Thoughts on writing a puzzler
There are at least two places where the puzzler's code could have been simplified without sacrificing its quality:
Replace explicit calls that delete the files /testdir/file and /testdir/symlink, with a communicated precondition that /testdir had no files.
This test has an interim call that computes the canonical path of a symlink that points to nothing, leading people to spend too much time worrying about that case. A better snippet would:
point the symlink to a file that exists.
compute the symlink's canonical location thereby (optionally) populating the internal cache.
point the symlink to a second file that also exists.
Last night I published a Java puzzler for your enjoyment. I will publish the answer tomorrow, but for now I thought you would enjoy an interim count of the guesses:
There's still plenty of time to participate in the puzzler. Don't forget to use the text box if you want to back up your reasoning.
Update: If you're reading this post in Google Reader, view the original page to participate in the survey.
Here's a little Java puzzler I encountered back in August. Essentially, the test below creates a symlink to /testdir/file, and validates that the symlink is in fact pointing to it.
This test was run on a Mac Book Pro running OSX 10.5.8 using a 1.5.0 JVM, though I originally discovered this problem using Linux and a Java 1.6 VM. The path /testdir is not a symbolic link to another directory, and the user running the test also owns /testdir.
import java.io.*;
import junit.framework.TestCase;
public class ATest extends TestCase {
public void testSymlink() throws Exception {
// Setup
run("/bin/rm", "/testdir/file", "/testdir/symlink");
run("/usr/bin/touch", "/testdir/file");
File TESTDIR_SYMLINK = new File("/testdir/symlink");
// Symlink doesn't exist yet
assertFalse(TESTDIR_SYMLINK.exists());
// And so its canonical path points to itself.
assertEquals("/testdir/symlink", TESTDIR_SYMLINK.getCanonicalPath());
// Now point the symlink to the file.
run("/bin/ln", "-s", "/testdir/file", "/testdir/symlink");
// The symlink exists
assertTrue(TESTDIR_SYMLINK.exists());
// The canonical path should be up to date.
assertEquals("/testdir/file", TESTDIR_SYMLINK.getCanonicalPath());
}
private static void run(String... args)
throws IOException, InterruptedException {
new ProcessBuilder(args).start().waitFor();
}
}
These are your choices. Try to determine the answer by solely looking at the sample code. Vote for your preference, and I'll publish the results along with the correct answer.
Voting is open until some time early Wednesday morning, Oct 21.
Our talk in August at Eclipse Day at the Googleplex focused on what it's like to support a large number of users in an enterprise. Dwelling in this question got me thinking about what kind of Eclipse user I might have been five years ago, and so I looked up the first message I ever posted to our internal mailing list for Eclipse users.
I have been a Google employee for just over five years, and have only spent the latter three supporting Eclipse for my colleagues. At the time of this dialogue, I'd been at Google for less than two months, and my Eclipse experience was limited to about 18 months of mostly untrained use.
Before you bother reading it, pleasedo not waste time troubleshooting the problem -- that's not the point if this post. This is a five year old issue, after all.
Robert Konigsberg
to <eclipse mailing list>
Subject: Problem with Eclipse 3.0 installation
10/10/2004
Hi all,
This afternoon I was working pretty happily in my Eclipse environment. All of I sudden I got a message telling me that I ran out of heap space, and advised me how to change my heap space. It offered to shut down Eclipse. I said "no". saved some work and quit myself.
When I tried to restart Eclipse I got all sorts of odd stuff. I can open Eclipse, but if I try to open the Java perspective, I get the error, "Problems opening perspective 'org.eclipse.jdt.ui.JavaPerspective'. Restarting my machine didn't help. When I try to edit Java preferences, I get similar errors.
Thoughts? Steve, is it Upgrade-To-3.0.1-Day for me?
Cedric Beust
to Robert Konigsberg, <eclipse mailing list>
Re: Problem with Eclipse 3.0 installation
10/11/2004
What does your .log say? Is it running out of heap space at each launch? In which case, I suggest to launch Eclipse with more heap:
eclipse -vmargs -Xmx600M
Robert Konigsberg
to Cedric Beust
cc <eclipse mailing list>
Re: Problem with Eclipse 3.0 installation
10/11/2004
Don't know which .log I'm looking for. Note below (edited for readability)
Cedric Beust
to Robert Konigsberg
cc <eclipse mailing list>
Re: Problem with Eclipse 3.0 installation
10/11/2004
Sorry, should have been more specific...
The .log file is in your ${eclipse-workspace}/.metadata directory.
I've removed the rest of the dialogue. Suffice it to say that it was probably a JDT index corruption issue that was resolved by removing the workspace-root/.metadata/.plugins/org.eclipse.core.resources/.root directory.
Here's the point: it's a little embarrassing to see that while I've attained some expertise in this domain, even I had no idea where the workspace log was. Also, I called it the "Eclipse environment" which is kind of a little wrong.
I appreciated both the memory and the mild feeling of humiliation that came with pulling up this old email.
Note: this post in no way suggests that Google Collections is wasteful. Quite the opposite, it's spectacularly awesome. If you haven't used it yet, go get it, play with it, discover appropriate uses of its power, and go rock your project.
Several months ago there was a discussion on one of the mailing lists at work about preference of part of the Google Collections API over an imperative equivalent. Specifically, using Iterables.transform to translate a List<X> into List<Y> by creating a Function that translates X into Y. In other words, which was better?
There was this argument about the value of the functional style over the imperative style, and frankly, I found it all rather confusing. All things being equal, the former was just too damn much. And that's the key here: all things being equal. If we were using a language with proper closures, or if there was a host of Function instances available to substitute for function, I might have (and have had) a different opinion.
To illustrate my point, I submitted this story to the mailing list.
Me: Kevin, tell me a story.
Kevin: Seriously. Go away.
Me: TELL!!
Kevin: OK. Once upon a time there was a programmer. He wanted a List. of Strings. But unfortunately, he had a List of Another Type.
Me: What type?
Kevin: Doesn't matter.
Me: WHAT TYYYYYPE!
Kevin: DOESN'T. MATTER.
Me: Ice Cream?
Kevin: Ice Cream. Fine Ice Cream. So the programmer...
Me: How much ice cream?
Kevin: What?
Me: How MUCH?
Kevin: Well, let me put it this way: if it was a List of ice cream, it would be A LOT of ice cream.
Me: Eeeeeeee!
Kevin: (pause) So... this programmer decided to take the list and return a New List. He decided to transform his list by creating a magical function that converts Another Type ... I mean ... _ice cream_ into Strings. And that Function has a method called 'apply'. Apply takes things of type ... sigh ... _ice cream_ and converts it to strings. It does this by calling its callStringMethod. The End.
Me: Wha?
--- REWIND
Kevin ... it would be A LOT of ice cream.
Me: Eeeeeeee!
Kevin: (pause) So... this programmer created a new, empty list. A place to store the Strings. And then he went through every _ice cream_ element in the old list, called its callString Method, and added it to the new list. And then he returned that list. The end.
Me: *sob* that is so awesome. What happened to the ice cream?
Kevin: I think Josh has it. Hurry up before he eats it.
Nobody here is saying that functional programming is bad or wrong. But sometimes it's not really all that awesome to be cutting edge.
Update: What I mean to say, that my colleague said in much fewer words, is that the primary concern in coding should be making your intention as plain as possible.
C++
I don't understand all the fuss
If you want a scoped pointer
Find a lady and anoint her
with watching your mem-o-ree!
Oh I want -- to -- go -- back -- to -- C.
With its malloc and its free
I just get so confused with delete and new
And what deletes who
And comparing an int to a boo-lee-an
I won't ever write a for loop
Thanks to Bjorne Stroutroup
And Alexander Stepanov
And I'll bet you've had enouv
of this poem.
I've enjoyed observing all the discussion around the new features to make it in to Java 7. All this time I've had an idea about a language feature which I've occasionally mentioned to colleagues, and it's around the domain of exceptions.
Before I discuss the problem, or my proposed solution, let me be frank: I'm no language expert. I have no expectations that a suggestion such as this has a chance of getting in to Java 8 if they can't even get multi-line strings into Java 7. I don't even care about the impurities brought up by this proposal. What I do care about is discussing a more graceful way of dealing with exceptions.
I'll agree with some of the fundamental concerns Misko Hevery brings up around the domain of checked exceptions. People often don't know what to do with them. Sometimes people just throw Exceptions into RuntimeExceptions and propogate them up the call stack. People also tend to overuse existing exception classes when one more specific to the a class or API domain would do. As is well documented in Effective Java (2ed) Item 61: Throw Exceptions appropriate to the abstraction. However, this all too often requires an undesirable amout of boilerplate code, and I do mean boilerplate. How many Exception classes have you written that look like this?
class MyException extends RuntimeException {
public MyException() { super(); }
public MyException(String message) { super(message); }
public MyException(Throwable cause) { super(cause); }
public MyException(String m, Throwable c) { super(m, c); }
}
Unless all your methods throw Exception, or if you only throw RuntimeException, IllegalArgumentException, and AssertionError, the answer is: you've written them plenty of times, and unless you're building an API to be consumed by the tens of thousands of engineers, you're probably not creating abstraction-appropriate exceptions often enough, directly against the advice of Effective Java.
What I propose is lowing the barrier for creating an exception class, which I'm calling Exception Sugar. Again, being no language maven, with no regard to syntax or grammar, I humbly propose:
exception className extends baseClass;
which serves as syntactic sugar for creating a subclass of baseClass named className that also, and here's the nasty part, "inherits" the base class's constructors. Yes, I know damn well that constructors aren't methods; they don't have instance scope, and there's really no such thing as constructor inheritance. I read Jeremy Manson's blog, and he even talks about the worthlessness of constructors. I get it. I couldn't care less. I just want to make it easier to write exception classes. To avoid the term inheritence I'll call it constructor propagation.
Maybe you don't like the proposed syntax. What about:
class className extends baseClass { propogate_ctors(); }
or
@ExceptionSugar className extends baseClass {}
Did you hear that? That, my friends, was the sound of a thousand shattering coffee cups from Java programmers whose grips loosened uncontrollably from the awful syntax. Relax, girls and boys. I'm not trying to sell syntax. I'm just trying to sell an idea. Get over the syntax, and mop up your coffee.
Q: Why can't you write your own exception class?
A. I might get it wrong. And I want to do it a lot. I want to make creating a domain-specific exception class even easier than creating a class for the domain.
Q: How could you use Exception Sugar to create subclasses that have additional attributes, or slightly different constructors?
A: I don't have any illusion of doing so. It seems to me that 99% of the time, people want to subclass Exception or RuntimeException, and even then, they only define just one constructor instead of all four.
Q: Why can't constructor propagation be applied to non-exception classes? Why should exceptions be the, ahem, exception?
A: Ha ha nice one. They don't have to be, but I'm not interested in easily propagating for classes outside the exception hierarchy. But if I'm pressed, constructor propagation in non-exception classes is almost certainly a Bad Idea, but am not going down that path tonight.
Q: Why not focus on something more valuable, like properties?
A: Properties sounds like a good idea. Go for it. The reason I bring up this particular idea is because I don't see anyone else thinking about it. That isn't to say I haven't brought it up before. I even mentioned it to Alex Buckley at last year's EclipseCon. Poor Alex, it was 1:30AM, and he and I somehow managed to win the party that evening, and so he had to suffer listening to yet another armchair language designer. But I will say, when I mentioned exceptions, he thought I was referring to catching multiple exception types. At least he was surprised, which means the idea might be awful.
Or awfully brilliant!
To be fair, Alex described some of the details that demonstrate the difficulty of this idea, but the combination of many drinks and the late hour made it impossible to understand. (Sorry, Alex.)
But getting back to the value of such a proposal: if people can propose literals with underbars and the Elvis operator, I can talk about this, too. (Don't get me wrong, I very much want the Elvis operator.)
As a conclusion of sorts, I'm about 95% confident there's a technical reason for prohibiting Exception Sugar, and about 99% confident it would never make it in to Java. I'd be honored if someone with an understanding greater than mine of Java and language design would be willing to comment on this idea, and provide some thoughts about the technical issues, if at least to educate.
Thanks for reading. Thanks to David Mankin for his feedback.
In June I made some general comments about Eclipse contributions, using the poor toString generator as my target. Fundamentally I still think Cay Horstmann's arguments are valid, but also, sometimes a partially complete solution is better than no solution at all.* and I realize this is one of those times. Today I needed to generate a toString method merely for the benefit of giving a nice view while debugging my application. In such a case, the toString generator came through like a charm, generating a nice, simple, clean implementation. Neat. Thanks, Mateusz.
* Sometimes a partially complete solution is worse than no idea at all.
The videos and slides from Eclipse Day at the Googleplex have been published.. You can find the slides on the Eclipse Foundation's wiki and the videos on the Google Open Source Program's blog.
The day finally came: Eclipse Day at the Googleplex, 2009. This event was hosted by the Google Open Source Program Office, and really, they did a great job. Seriously big thanks to Chris, Leslie, Cat and Ellen, who put together a fantastic program. Except for the forks. (Note to self: Even if Eclipse Day lunch has no forks, I must no longer try stealing forks from a Google cafeteria. You'll get caught and questioned by the cafeteria manager.)
But also I have to thank Ian Skerrett and Lynn of the Eclipse Foundation for putting so much together on their side of the event. Ian is actually sitting right next to me: we're listening to one of the final talks "Google Plugin for Eclipse: Not Just for Newbies Anymore" given by my Google colleague, Miguel Méndez. Miguel just demonstrated how the Google Plugin for Eclipse deals with launch configurations. I'm drooling.
My teammate, Terry Parker, and I gave the keynote presentation, titled "Eclipse in the Enterprise: Lessons from Google" which was a glimpse into what it takes to support all the people at Google who build applications with Eclipse:
Providing Eclipse tools to thousands of engineers at Google is a satisfying job, but it's not always easy. In the last two years Eclipse has gone from being a tool supported by enthusiasts in their spare time to one supported by a team mandated to make engineers' lives better. We will talk about the plug-ins we've written and processes we've established to provide features, enterprise deployment and support, and even share some of the pitfalls discovered along the way.
I wasn't sure how the talk would be received, but it sure seems to have gone over well. Slides are coming shortly, as is, I hope, a YouTube video.
Along those same lines, Joep Rottinghuis from eBay talked about Deploying Successful Enterprise Tools, and it was serendipitous since he managed to touch on all the facets of enterprise tool support that we omitted from our talk: support, documentation and training.
The best part, though, was how people from both eBay and Cisco told us that they were happy to see us talking about the scalability issues we've seen; they have the same problems!
All of this underscores what I have thought since last year's EclipseCon: next year I'd like to see an Enterprise Tools BoF.
Ooh, gotta go: now Miguel is talking about adding special JSNI formatting in editors. Swoon!
In the last year or so I've become addicted to a puzzle game known as Slitherlink. Here's the premise of the game, as described on Wikipedia:
Slitherlink is played on a rectangular lattice of dots. Some of the squares formed by the dots have numbers inside them. The objective is to connect horizontally and vertically adjacent dots so that the lines form a single loop with no loose ends. In addition, the number inside a square represents how many of its four sides are segments in the loop.
Other shapes can be used in lieu of the standard grid, as long as each tile has 4 sides. These include snowflake, penrose, laves and altair. They add complexity by increasing the possible paths from an intersection, but the same rules apply to their solution.
If that didn't make sense, let me show you a fairly simple version of this puzzle. Starting with this unfilled grid,
one of the first things you can spot is the cell with a '0'. A zero means that none of the segments around it are used in the final loop. So one of the first things I can do is remove those four neighboring segments.
Now let's look at the neighboring cell with a '3'. Since one of the four neighboring segments have been removed, it's obvious that the other three lines participate in the loop.
This goes on until the puzzle is solved.
The version It's available as part of Simon Tatham's Portable Puzzle Collection, but there it's called Loopy. One of the nice things about Loopy is that it provides different difficulty levels, and formats other than squares.
After playing for a while you get a good sense of strategies and can play more and more difficult variants. Here's one that I worked on for almost four hours until discovering a problem in the upper right corner.
Variants
With regards to using dictionaries and online tools to solve crosswords, Will Shortz credits his predecessor at the New York Times with this quote: "It's your puzzle. Solve it any way you want." Similarly, you can solve Loopy puzzles any way you want. Here are some of the variants I've come up with while playing:
Speculation: Since Loopy allows you infinite levels of undo, it's easy to use speculation as a puzzle-solving tactic. For instance, if you're not sure whether a particular line segment is part of the loop, you can merely start traversing in a direction to see what follows. If you're taken to an impossible position, you know your guess was wrong, and that the opposite of your guess is correct; a proof-by-contradiction if you will.
There are problems with the speculation variant, though. One is that it only really provides information when your guess turns out to be wrong (unless your guess leads you to completing the loop.) If your guess is correct, or perhaps it just leads you to another position that requires more speculation, you get no concrete information. So using speculation requires making good choices: speculate in small areas where you'll quickly corner yourself.
Another problem with speculation is that you have to remember where you made your guess. While undoing your guesses, if you're not careful, you'll undo too much, or worse, not enough. How I typically address this is by clicking on my guess so many times that when rapidly undoing, it also undoes my many clicks, so visually it looks like a rapid flash.
No speculation: After learning more and more solving techniques, you have less of a need to speculate on the board, and can either solve more complex parts of a puzzle in your head, or better, handle speculating in your head. The no-speculation variant just means just that: no speculating is allowed. If you mark a segment in the puzzle as part of the loop, or not in the loop, it's because you know it to be so. The four-hour mega cairo puzzle above was played with no-speculation.
No undo: A variant of no-speculation, but it requires surprisingly more focus and hand-eye-coordination. When I typically play no-speculation, if I accidentally mark a segment I didn't intend to, I just undo and correct it. No-undo basically means, no undo. It's not quite the same as choosing to solve a crossword puzzle with a pencil or pen, particularly for larger puzzles. Very often you find yourself seeing several obvious steps, and you're bound to make a mistake if you're lazy or not paying attention.
Mark segments only: Although I haven't explicitly said this yet, every segment in the loop can be in one of three states: undecided, on-the-loop or off-the-loop. (These can be seen in these screen captures as yellow, grey and black.) Clicking on an unmarked segment marks it as on-the-loop; right-clicking marks a segment as off-the-loop. On a Mac, there's no right-click -- you have to press the command key in conjunction with a click. So while you can play one-handed on Loopy for Windows, you can't play one-handed on Loopy for Mac. So I discovered this variant where you were only allowed to mark lines as part of the loop. No marking lines as off-the-loop.
This makes the game considerably more difficult. Any segments that you know are off the loop have to be managed by your brain. I tend to not play this variant too often.
Here's a partially completed puzzle. On the left only segments in the loop are marked. If I also marked segments that are not in the loop, the puzzle would look like the one on the right, and there are already three superbly obvious segments in the loop.
Clear only: The opposite of mark segments only. You can only mark those segments that are off the loop, at least, until the puzzle is complete. I've discovered some interesting strategies trying to solve puzzles with this restriction.
Here's another partially completed puzzle. On the left only segments out of the loop are marked. Marking segments that I know are in the loop provides much more information.
This is currently my favorite way to play.
Clear only, one continuous segment: This is basically the same as the clear only variant with one additional rule: you can mark segments in the loop, but all segments in the loop must be connected to each other. This is a slightly easier variant than clear only,
Basically you start the game like you're playing clear only and when you find it most valuable, start a line segment.
In the sample puzzle above it's obvious that everything in the lower right corner of the puzzle is on the loop, but they can't be marked as such. The lower left also has some obvious spots. Maybe in a couple of moves I can connect the lower left to the single segment.
When playing this variant I tend to keep my board free from a single segment for quite a long time. Often if I want to mark a region, the marking doesn't necessarily buy me anything. So I often find thinking about creating a segment as a way to study the puzzle.
On paper: Try printing the puzzles on paper. It feels like an entirely different puzzle.
Conclusion
If you haven't tried Loopy, I suggest you do. If you have limited time during your day, I suggest you play something else.
But if you do play Loopy, by what rules do you play?
Update: Writing this post encouraged me to do try a large puzzle again, but this time playing clear-only, one continuous segment. no speculation. I'm just getting started, as you see.
Update: (Sunday 10AM) I've clarified the way to play clear only, one continuous segment.
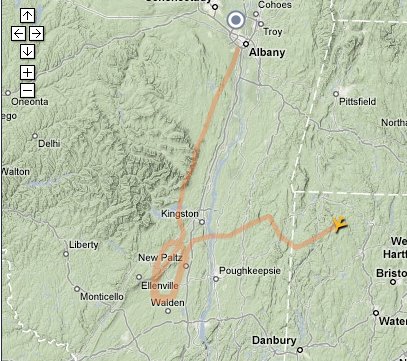
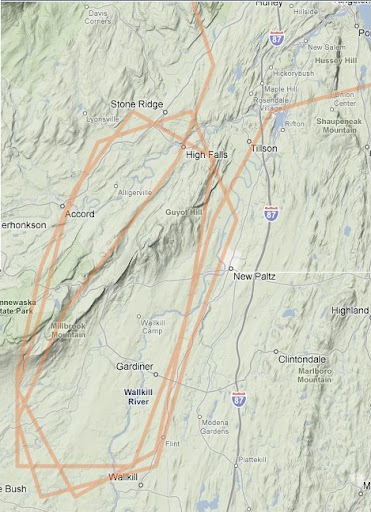
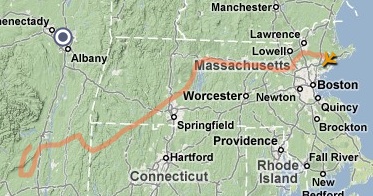
My cousin Judy is visiting from London. She had a flght from Heathrow to Newark, but given today's awful weather, she was redirected to Albany, about three hours from Newark by car. Because Albany's airport isn't prepared to handle immigration, she could not disembark.
After over three hours on the ground, the flight finally left for Newark.
when to made several rotations around an arbitrary area
PSE&G only allows you to set up one customer service account per email address. So, if you live on one property in their service area, and then move to another property in their service area, you must register a new account with a brand new email address.
I'm genuinely still a little shocked. No matter how hard I tried, I could not find a way to either add a second account or remove the first one to my email address. I messed with pseg.com for 15 minutes, so I called them for help. After 20 minutes on hold, I asked how to change the account. The customer service representative told me, no, I couldn't do that, I had to create a new account. Being hasty, I thanked the CSR and ended the call, assuming he was just wrong.
Registering a second account with the same address failed. Registering a second account with email+pseg@domain.com also failed, not because it was a duplicate but because PSE&G considers that an invalid email address. Honestly, not much of a surprise, that.
So I called again. Was it really like that? After another 20-minute hold (whoo, these guys are popular) I confirmed with a second CSR that, yes, really, it was like that. She said I should just "create another email at like yahoo mail." The CSR agreed to lodge my complaint and I rung off for the second time.
I have one email address upon which I rely, the destination of all my important personal correspondence. Why should PSE&G email have to be delivered elsewhere? I could create a second account whose purpose is merely to forward all mail to the primary one. I refuse to have to remember a new email account just to pay my electric bill. I'm still hoping that one day all my accounts can be registered through OpenID, so this is somewhat the opposite of that goal.
Perhaps people are so dissatisfied with PSE&G that they vow to move out of their service area before ever using them again?
This is a bug, plain and simple. Most likely a bug in requirements or design. And it got me thinking: what different developement phases might have created such a problem?
Requirements gathering phase: perhaps nobody mentioned this as a possibility. Better still, someone mentioned it as a very rare occurrence.
Design phase: maybe this was an intentional design decision. Maybe they don't particularly care about account history as a person moves between properties.
Database design: assuming a SQL database back-end, perhaps the whole product is wrapped around a database that has a single table called ACCOUNT with columns email_address and account_id. perhaps they can get a lesson in Third Normal Form.
User acceptance testing: perhaps no managers or testers had recently moved within the PSE&G service area, if at all.
Middle-tier design: first thing I'd do is grep for function createaccount($emailaddress, $accountid)
Contract negotiations: The back-end support team has a charging structure based on the number of accounts.
UI design: I ... can't really find a way that UI design gets in the way. Here's the registration form. Maybe you can see something.
In my many years working in the pharma consulting industry, there was a common phrase for difficult non non-negotiable tasks: Phase 2. Could this just have been considered a Phase 2 project, complete with database normalization redesign?
Could be. After all, this consumer site is just over 100 days-old.
Java 5.0 introduced Generics. It also introduced covariant return types. Wikipedia does a fine job describing covariant return types.
Since they were released simultaneously, I consider them to be tightly coupled. For instance, here are simplified versions of an interface and implementation I recently wrote:
Note: I am having difficulty representing greater-than and less-than symbols in Blogger's editor, so you'll have to do with { and }.
Version 1: Java 5, Generics, Covariant return types
public interface Model{T extends Model{T}} { T read(InputStream in); T write(OutputStream out); }
public class MyModel implements Model{MyModel} { public MyModel read(InputStream in) {
...
} public MyModel write(OutputStream out) {
...
} public MyModel setName(String name) {
...
return this;
}
public String getName() { ... } }
Thanks to the covariance, I can write a method chain like this:
new MyModel()
.read(in)
.setName("foo")
.setStopAtMain(false)
...
.write(out);
With Java 1.4, the code would have to look like this
Version 2: Java 1.4
public interface Model { Model read(InputStream in); Model write(OutputStream out); }
class MyModel implements Model { public Model read(InputStream in) { ... } public Model write(OutputStream out) { ... } ...
}
And the method chain would result in a syntax error:
public static void foo() { new MyModel() .read(in) .setName("foo") ^ The method setName(String) is undefined
for the type Model. .write(out); }
Which you could hack around with an ugly cast:
public static void foo() { ((MyModel) new MyModel() .read(in)) .setName("foo") .write(out); }
Back to the Java 5 example: My point is just this: covariant return types don't require generics. All that messy code in version 1 could look much simpler because covariant return types exist on their own without generics:
Version 3: Java 5, Covariant return types
public interface Model{T extends Model{T}} { T Model read(InputStream in); T Model write(OutputStream out); }
public class MyModel implements Model{MyModel} { public MyModel read(InputStream in) {
...
} public MyModel write(OutputStream out) {
...
} public MyModel setName(String name) {
...
return this;
}
public String getName() { ... } }
Lesson learned: I know generics fairly well, but there's a difference between knowing when it's useful and when it isn't. Said another way: when you have a Generic hammer everything looks like a generic nail.
This evening I read Cay Hortmann's article on upgrading to Galileo. (For those of you who do not know Cay, he writes the fantastic Core Java books. I learned Java from the 1.1 version, as well as both the 1.4 and 1.5 versions. He writes great stuff.)
In the article he makes this comment:
There is now an option to generate toString automatically. This is something I've wanted for a long time. Unfortunately, it is not very good. Core Java gives these simple rules for toString:
Use getClass().getName() to print the class name. Then your toString can be inherited.
When you redefine toString in a subclass, first call super.toString(), then add the subclass data.
The Eclipse formatter follows neither of these eminently sensible rules. Maybe in 3.6.
I've not yet seen the toString generator, but having written more than enough toString implementations, I've worried that such a code generator may be less than ideal. Similarly, I've seen the equals and hashCode generators at work, and I also tend to not want to use them.
Given that I work for a company that has so much Java code that "If code was ice cream, it would be a lot of ice cream," [Ref Java Posse 240, 9:15] in addition to having very helpful helper methods for hashCode and equals, I'd love more finely-tuned generators for such critical methods.
As the Contribution Rule reminds us, “Everything is a contribution.” And with many contributions, the possibilities are endless.
OK, so let's say I write my own generators for toString, hashCode and equals. Then there are two toString generators in the IDE, one possibly better than the other. Why should the end user be forced to deal with two confusing UI contributions?
Sure, there's also the recent object of my affections, patch fragments, but the patch fragment is a back-door lover.
I want to remove the default contributions altogether, and replace them with something better suited to my environment. But that violates the Contribution Rule. Am I stuck with something less than ideal until Eclipse 3.6, or worse, forever?
What's the solution here?
PS: Has someone picked up on Cay's concerns and logged a bug?